Retourner à : Librairies Python à connaître
Ca vous est déjà arrivé de travailler sur une application python et de devoir importer ou exporter des données à partir ou vers un fichier Excel? Votre première idée était d’utiliser le format CSV, mais votre client insiste sur un fichier Excel avec plusieurs tabs et des formatages spécifiques. Ce tuto est faite pour vous.
Aujourd’hui on va regarder comment utiliser la librairie Pandas pour :
- Lire des fichier Excel avec un ou plusieurs tabs
- Faire quelque manipulations de base sur les données lues
- On va regarder comment écrire un fichier Excel à partir d’un tableau d’objets qu’on souhaiterais exporter
- Et pour finir on verra comment appliquer des formatages un peu plus avancés
Introduction
Pandas est une bibliothèque open-source Python qui permet de manipulater et d’analyser de données. Elle offre des structures de données rapides et flexibles pour stocker des données, notamment des tableaux à deux dimensions appelés DataFrames, qui ressemblent à des feuilles de calcul Excel. Pandas est particulièrement utile pour la manipulation de données, que ce soit pour la transformation, l’analyse statistique ou pour encore importer et exporter des données dans divers formats. Et ça tombe bien bien car le format Excel en fait partie, comme le CSV et bien d’autres.
Installation
Maintenant qu’on a vu ce qu’est pandas, regardons comment lire notre fichier Excel. Avant d’installer pandas, je propose qu’on crée d’abord un environment virtuel. Pour cela on va dans notre terminal, on se rend dans le dossier ou on veut créer notre nouveau projet, on tape:
virtualenv -m python3 .venvOuvrons maintenant notre éditeur de code, et ouvrons notre projet. Normalement que vous soyez sous PyCharm ou VSCode, votre éditeur devrait automatiquement détecter l’environment virtuel et l’utiliser par défaut. Mais si ce n’est pas le cas vous pouvez modifier l’interpreter de votre projet dans les paramètre de votre éditeur. Pour ma part, je vous montrerai comment installer vos dépendances et comment lancer votre code dans le terminal, comme ça vous pourrez suivre ce tutoriel indépendamment de votre éditeur.
La première chose qu’on va faire c’est qu’on va installer pandas, pour cela je vous conseille de créer un fichier « requirements.txt » et à l’intérieur duquel on va ajouter la ligne suivante:
pandasMaintenant, dans notre terminal, on active notre environnement en faisant un:
source .venv/bin/activateEt pour installer les dépendances qu’on a ajouté au fichier « requirements.txt » on va tapper:
pip install -r requirements.txtLecture d’un fichier Excel
Une fois les dépendances installer on peut passer aux choses sérieuses et lire un fichier Excel. Ici vous retrouverez un fichier avec un tab « people », qui contient des noms et prénoms de personnes, ainsi que leurs ages et leur dates de naissances, et un tab « cars » avec entre autre, des informations sur des models de voiture ainsi que leur année de production. Pour cet exercice, j’ai stocké ce ficher à l’intérieur du dossier de notre projet dans un sous-dossier « input ».
Pour lire ce fichier, on va créer un fichier python qu’on va appeler « main.py », et dans ce fichier on va écrire le code suivant:
import pandas as pd
SAMPLE_PERSON_EXCEL = 'input/sample_people_data.xlsx'
def read_example(input_path):
df_people = pd.read_excel(input_path)
print(df_people)
if __name__ == '__main__':
read_example(SAMPLE_PERSON_EXCEL)Ici on a tout d’abord importé pandas, et puis on a défini la fonction « read_example », qui prend en entrée le chemin d’accès au fichier qu’on veut lire. Pour lire ce fichier il suffit simplement d’utiliser la méthode read_excel de pandas, en lui passant le chemin en question. Et si on imprime le tout et qu’on execute notre code on a le résultat suivant:
ImportError: Missing optional dependency 'openpyxl'. Use pip or conda to install openpyxl.Et oui, on a une exception, mais c’est normal, et si on lit l’exception on voit qu’elle nous dit qu’il nous manque une dépendance afin de pouvoir manipuler les fichier excel, et la dépendance en question est la bibliothèque « openpyxl », donc ajoutons là à notre fichier « requirements.txt »:
pandas
openpyxlet installons là:
pip install -r requirements.txtEt si on relance notre programme, vous voyez qu’on a bien réuçi à lire le fichier Excel et à le stocker dans notre variable df.
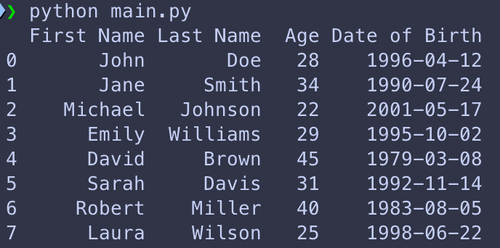
Si vous voulez lire plusieurs tabs, ou un tab spécifique, pandas peut le faire, pour cela il suffit de passer à la méthode read_excel le nom du tab que vous voulez lire:
def read_excel(input_path):
df_people = pd.read_excel(input_path)
df_cars = pd.read_excel(input_path, sheet_name='cars')
print(df_people)
print("=" * 50)
print(df_cars)Ici, on obtient :
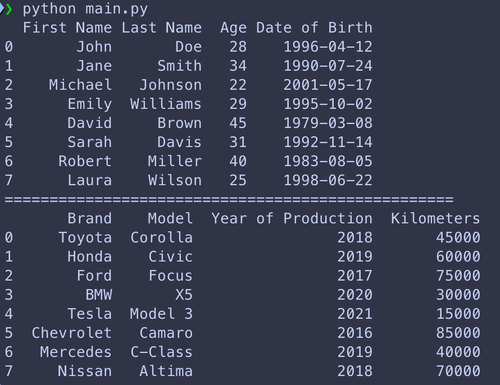
Manipulation des données
Maintenant accéder et utiliser les données qu’on vient de lire est plutôt simple. Par example si on souhaite imprimer la colonne « Age » de notre tableau de personnes il suffit de renseigner le nom de la colonne entre crochets à notre « DataFrame »:
def read_excel(input_path):
df_people = pd.read_excel(input_path)
df_cars = pd.read_excel(input_path, sheet_name='cars')
print(df_people['Age'])Et on obtient le résultat suivant:
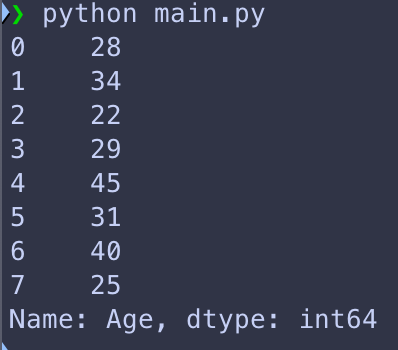
Maintenant si on souhaite multiplier toute la colonne par 2 on peut le faire, comme on le ferrai pour une multiplication normale:
def read_excel(input_path):
df_people = pd.read_excel(input_path)
df_cars = pd.read_excel(input_path, sheet_name='cars')
print(df_people['Age'] * 2)Et la notre colonne toute entière est multipliée par 2.
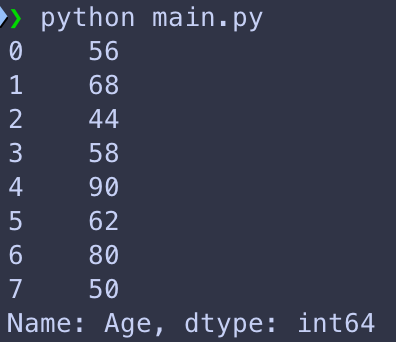
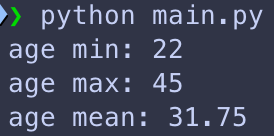
On peut aussi calculer quelques statistiques de cette colonne, comme par example son minium, son maximum et sa moyenne, en utilisant les fonctions « min() », « max() » et « mean() »:
def read_excel(input_path):
df_people = pd.read_excel(input_path)
df_cars = pd.read_excel(input_path, sheet_name='cars')
age_min = df_people['Age'].min()
age_max = df_people['Age'].max()
age_mean = df_people['Age'].mean()
print(f"age min: {age_min}")
print(f"age max: {age_max}")
print(f"age mean: {age_mean}")En faisant cela on obtient:
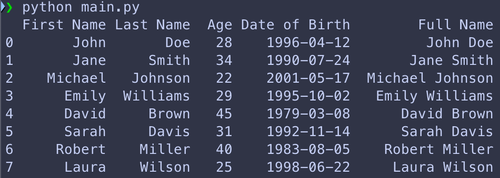
Un autre cas d’usage, serait de créer une nouvelle colonne à partir de deux colonnes existantes. Pour cela il suffit d’assigner à notre « DataFrame » le résultat d’une opération sur deux colonnes en spécifiant entre crochets le nom de la nouvelle colonne.
def read_excel(input_path):
df_people = pd.read_excel(input_path)
df_cars = pd.read_excel(input_path, sheet_name='cars')
df_people['Full Name'] = df_people['First Name'] + ' ' + df_people['Last Name']
print(df_people)ce qui nous donne:
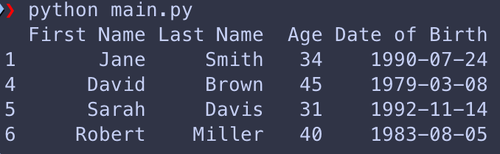
On peut aussi filtrer les lignes de nos « DataFrames » en passant entre crochets une condition sur une colonne. Donc si on ne veut récupérer que les personnes qui ont plus de 30 ans, on peut faire la chose suivante:
def read_excel(input_path):
df_people = pd.read_excel(input_path)
df_cars = pd.read_excel(input_path, sheet_name='cars')
df_people_over_30 = df_people[df_people['Age'] > 30]
print(df_people_over_30)et on obtient donc uniquement les lignes suivantes:
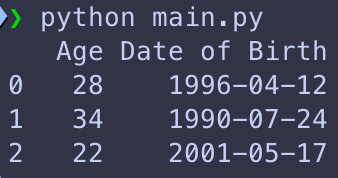
Maintenant imaginons qu’on ne veuille récupérer qu’un sous ensemble de données de notre « DataFrame » via leurs indexes. Dans notre example si on ne veut récupérer que les 3 premières personnes du tableau et uniquement leurs ages et dates de naissance, alors on peut utiliser la méthode « iloc » en passant entre crochets les indexes qui nous intéressent, donc les lignes « [0, 1, 2] » et les colonnes « [2,3] »:
def read_excel(input_path):
df_people = pd.read_excel(input_path)
df_cars = pd.read_excel(input_path, sheet_name='cars')
df_sub_people = df_people.iloc[[0,1,2], [2,3]]
print(df_sub_people)et on se retrouve avec le sous tableau suivant:
Des fois vous voudrez itérer à travers toutes les lignes de votre tableau, pour cela vous pouvez utiliser la méthode « iterrows() » du « DataFrame »:
def read_excel(input_path):
df_people = pd.read_excel(input_path)
df_cars = pd.read_excel(input_path, sheet_name='cars')
for index, row in df_people.iterrows():
print(f"Row {index} - First Name: {row['First Name']}")Ce qui nous donne le résultat:
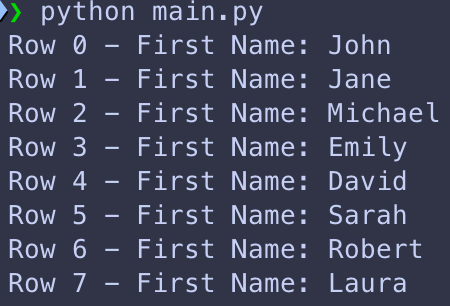
Ecriture d’un fichier Excel
Regardons comment écrire une liste d’objets python dans un fichier Excel. Pour cela on va utiliser en tant qu’exemple la classe « Car » ci-dessous:
class Car:
def __init__(self, brand: str, model: str, production: date):
self.brand = brand
self.model = model
self.production = productionLa première chose qu’on va faire c’est qu’on va ajouter une fonction « to_dict() » à notre classe, qui va nous renvoyer un dictionnaire avec les valeurs que nous souhaitons exporter:
class Car:
def __init__(self, brand: str, model: str, production: date):
self.brand = brand
self.model = model
self.production = production
def to_dict(self):
return {
'brand': self.brand,
'model': self.model,
'production': self.production
}Maintenant nous pouvons écrire une fonction write_excel qui va prendre le chemin vers le fichier que nous voulons générer:
def write_excel(output_path):
cars = [
Car('Nissan', 'A', date(2001, 4, 20)),
Car('BMW', 'B', date(2002, 2, 20)),
Car('Mercedes', 'C', date(2001, 3, 20)),
Car('Peugeot', 'D', date(2012, 7, 20))
]
df_cars = pd.DataFrame([car.to_dict() for car in cars])
df_cars.to_excel(output_path, sheet_name='cars', index=False)
if __name__ == '__main__':
write_excel(OUTPUT_SAMPLE_PATH)Dans cette fonction on a tout d’abord créé un tableau de voitures qu’on souhaite exporter, puis on a passé le tableau de dictionnaires qu’on a généré à partir de notre liste de voiture au constructeur de « pd.DataFrame ». Ceci nous a créé un « DataFrame » qu’on a appelé « df_cars » et puis on a sauvegardé ce « DataFrame » dans le fichier excel en utilisant la méthode « to_excel() ». Notez qu’on a passé à cette méthode en plus du chemin vers notre fichier, aussi le nom du tab à utiliser via le paramètre « sheet_name » et qu’on a également indiqué qu’on ne souhaite pas exporter en tant que première colonne les indexes du tableau. Et si on execute le code on obtient le fichier excel suivant:
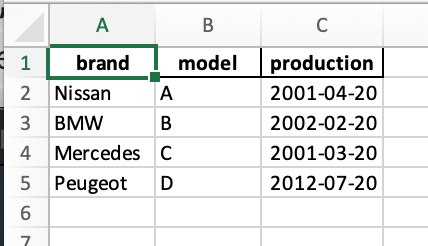
Formatage du fichier Excel
Maintenant qu’on sait faire un export vers Excel il est temps de voir comment formater notre fichier afin de lui donner un look plus plaisant. Pour cela on peut utiliser la librairie « xlsxwriter » qu’on va ajouter à notre fichier « requirements.txt »:
pandas
openpyxl
xlsxwriterEt qu’on installe comme d’habitude avec « pip »:
pip install -r requirements.txtMaintenant réécrivons notre fonction write_excel afin d’appliquer un font bleu foncé à nos titres, un fond blanc à toutes nos lignes paires et un fond bleu claire aux lignes impaires. En plus de cela j’aimerai que les dates aient le format « dd/mm/yyyy ».
def write_excel(output_path):
cars = [
Car('Nissan', 'A', date(2001, 4, 20)),
Car('BMW', 'B', date(2002, 2, 20)),
Car('Mercedes', 'C', date(2001, 3, 20)),
Car('Peugeot', 'D', date(2012, 7, 20))
]
df_cars = pd.DataFrame([car.to_dict() for car in cars])
ST_HEADER = {
'bold': True,
'bg_color': '#1F4E78',
'font_color': '#FFFFFF',
'border': 1
}
ST_EVEN = {
'border': 1,
'bg_color': '#FFFFFF',
}
ST_ODD = {
'border': 1,
'bg_color': '#d2f1f7',
}
ST_EVEN_DATE = {
**ST_EVEN,
'num_format': 'dd/mm/yyyy',
}
ST_ODD_DATE = {
**ST_ODD,
'num_format': 'dd/mm/yyyy',
}
with pd.ExcelWriter(output_path, engine='xlsxwriter') as writer:
df_cars.to_excel(writer, sheet_name='cars', index=False)
workbook = writer.book
worksheet = writer.sheets['cars']
header_format = workbook.add_format(ST_HEADER)
even_format = workbook.add_format(ST_EVEN)
odd_format = workbook.add_format(ST_ODD)
even_date_format = workbook.add_format(ST_EVEN_DATE)
odd_date_format = workbook.add_format(ST_ODD_DATE)
for col_num, value in enumerate(df_cars.columns.values):
worksheet.write(0, col_num, value, header_format)
for row_num in range(1, len(df_cars) + 1):
for col_num, column_name in enumerate(df_cars.columns):
cell_value = df_cars.iloc[row_num - 1, col_num]
if column_name == 'production':
date_format = even_date_format if row_num % 2 == 0 else odd_date_format
worksheet.write_datetime(row_num, col_num, cell_value, date_format)
else:
cell_format = even_format if row_num % 2 == 0 else odd_format
worksheet.write(row_num, col_num, cell_value, cell_format)Ici on a fait plusieurs choses:
- Tout d’abord on a créé des dictionnaires avec les différents styles qu’on souhaite appliquer à nos cellules. Pour cela on utilise différentes propriétés, tel que ‘border’, ‘bg_color’, ‘font-color’ ou encore ‘num_format’.
- Nous ouvrons le fichier dans lequel on souhaite écrire notre tableau excellent avec « pd.ExcelWriter ».
- Nous stockons le workbook, car on y défini par la suite les différents styles qu’on pourra utiliser pour nos cellules. Cette définition se fait en utilsant la méthode « workbook.add_format » et en lui passant en paramètre le dictionnaire qui contient le style à appliquer.
- Nous récupérons ensuite le tab « cars » grace à « writer.sheets[‘cars’] ». Nous en aurons besoin afin d’y écrire notre tableau.
- Puis nous avons un premier « for » qui va prendre chaque entête de notre tableau et lui appliquer le style « header_format » en utilisant la méthode « worksheet.write ».
- Ensuite on itère à travers toutes les cellules de notre tableau et si la cellule a le nom « production », alors la cellule est une date et on lui applique le format de date avec un fond blanc si la ligne est une ligne paire, sinon on lui applique le format de date avec un fond bleu claire. L’écriture de la cellule qui est une date se fait via la méthode « worksheet.write_datetime »
- Si on est face à une autre cellule on applique le style avec un arrière plan blanc si c’est une cellule paire, et le fond bleu claire autrement.
Une fois qu’on execute ce code on se retrouve avec l’Excel suivant:
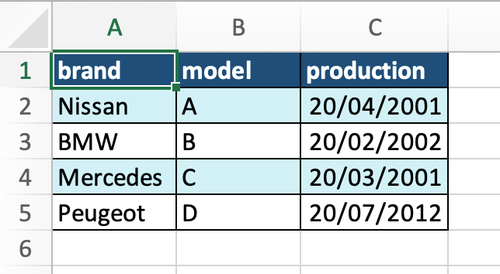
Et voilà, vous devriez maintenant être capable de générer de beaux Excels à partir de votre code Python.